JavaScript Fundamentals - Closure
This is a continuation of my previous post on fundamentals.
Like I mentioned in the previous post, JavaScript is a pretty unique and quite flexible language. As a result, it can sometimes feel magical - some things just work and you’re not quite sure why. Or maybe what you thought should work doesn’t and you find yourself doing some brute force debugging. This is by no means a comprehensive list, but they are some fundamentals that may give you more insight as to the inner workings of JS.
At the end of the post on scope, I left you with the below problem and asked what would get console logged.
Figure 1
function a(){
var example = 2;
return function b(){
console.log(example);
}
}
var example = 1;
var resultA = a();
var resultB = resultA();The answer is ‘2’. But how can it log ‘2’ if by the time b() gets invoked, a()’s execution stack has popped off.
That’s where closures come into play. Let’s start with the official MDN definition of a closure:
Closures are functions that refer to independent (free) variables (variables that are used locally, but defined in an enclosing scope). In other words, these functions ‘remember’ the environment in which they were created.
Now let’s take a look at a visual representation of the execution stack of the example above. Again, so sorry for the crappy drawings, but hopefully they get the point across.
I always imagine execution contexts as lock boxes that store our variables and keys that give us access to other boxes. If we don’t find what we’re looking for in one box, we can use the keys to search the other corresponding boxes. What keys are in a lock box are determined by the lexical scope. Every box contains at least one key, a key to the global scope.
Figure 2
function a(){
var example = 2;
return function b(){
console.log(example);
}
}
var example = 1;
var resultA = a();
var resultB = resultA();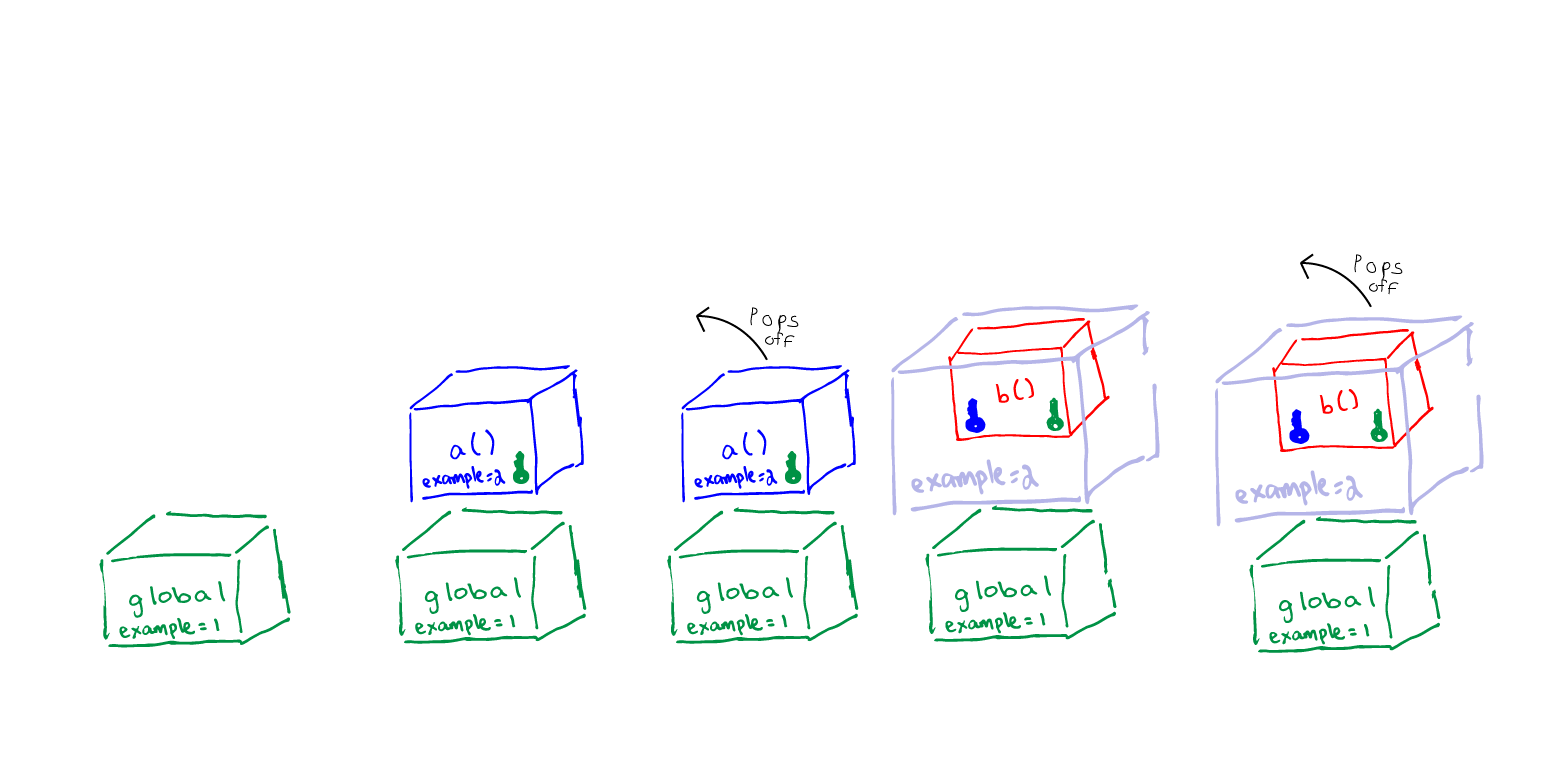
- Global execution context is created
- a() is invoked and it’s result (function b()) is stored in the variable resultA
- a() is done running and pops off the stack
- b() is invoked (resultA()) and a new execution context is created
- b() tries to console.log(example), but it does not find it inside of its own execution context
- But wait! b() still has a key to access a()’s execution context
- Here’s where closure comes in and saves the day. Even though a() has been popped off, JS creates a closure, which I picture as an almost ghost like version of a()’s context and because b() has that key to a(), it can go ahead and access var example = 2.
- ‘2’ gets console logged
- b() gets popped off
So what would be the closures in the example above. I would argue that it is 1:
Figure 3

However, my understanding is that you could also consider a closure between the functions and the global environment since var example = 1; would be the ‘free’ variable that function a() is ‘remembering’.
Figure 4

The reason I think of it as only one closure is that while you can create a closure lexically, in the sense that you decide where in your code to create what functions and variables, closures really come into play during execution. Consider the execution stack on Figure 2, to the execution stack below:
Figure 5
function b(){
console.log(example);
}
function a(){
var example = 2;
b();
}
var example = 1;
a()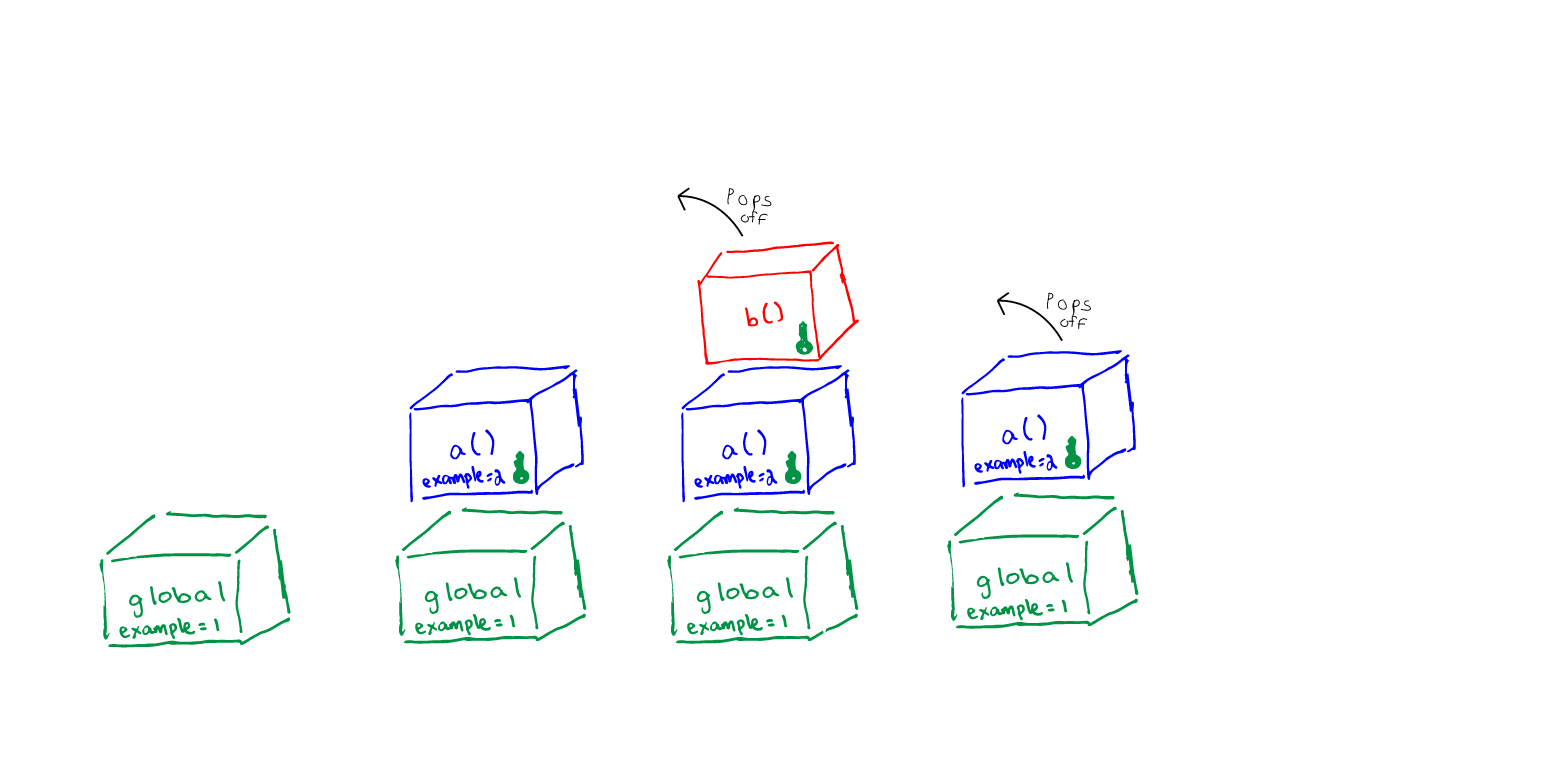
A closure was necessary in the first instance (Figure 2) because when b() was invoked, a()’s execution context was no longer ‘on’ the stack. No closure is needed in Figure 5 between a() and the global environment because there is no danger that the global context would be popped off before the invocation of a().
May call for some more research!